A Journey into Just-In-Time compilation in JavaScript — Part 6 — Inline Caches in SpiderMonkey
Hey guys, it’s been a while since the last post. In today’s post, we will be going through the workings on how the SpiderMonkey engine handles the Inline Cache code generation.
Inline Caches
From wikipedia
Inline caching is an optimization technique employed by some language runtimes. The goal of inline caching is to speed up runtime method binding by remembering the results of a previous method lookup directly at the call site. Inline caching is especially useful for dynamically typed languages where most if not all method binding happens at runtime and where virtual method tables often cannot be used.
The SpiderMonkey utilizes runtime information to generate Inline Caches. For this purpose, the SpiderMonkey uses a separate Intermediate Representation called CacheIR.
In abstract, what Inline Cache do is, instead of generically handling all the object types for each bytecode using an Interpreter, the Inline Cache utilizes the profiling information collected from previous iteration for the JavaScript code in the Interpreter and generate machine code that contains checks for guarding the assumptions collected from previous executions of the code and performs the operation of the bytecode. By this way, the engine will be able to avoid doing checks for all the datatypes and perform operation only on the current object.
ICScript
All the CacheIR(Inline Cache) code generated for a script is stored in the ICScript object. The ICScript object is stored at the end of the JitScript object. At the end of the ICScript object, we will have an array of pointers to ICEntry objects which contains the generated CacheIR code and the corresponding Machine code.
Exploration
Let’s explore how CacheIR code is generated for a specific JSOp bytecode in SpiderMonkey.
First, we need to trigger Baseline compilation in the SpiderMonkey to generate CacheIR code. The Baseline compilation is triggered in the SpiderMonkey when a Javascript code is executed more than 10 times inside the engine. So let’s create a for loop that executes more than 10 times.
let g = 10;
for(let i=0;i<11;i++){
g += 1;
}When we execute the above code, the SpiderMonkey will switch from Generic C++ interpreter to baseline interpreter. The baseline Interpreter, for each bytecode generated for the JavaScript code, will call its corresponding Fallback Inline Cache code generator. For analysis purpose, I have set a breakpoint in one of those Inline Cache code generator function which will generate Inline Cache code for the Binary Arithmetic operations and we have got a hit there.

The DoBinaryArithFallback function will perform the requested Binary arithmetic operation and tries to generate CacheIR code using the TryAttachStub function as shown below.

Once the CacheIR code is generated for the opcode ,it will be appended to the end of the JitScript. Let’s examine the JitScript to see the generated CacheIR code.
The JitScript is present inside the data_ pointer of the BaseScript as shown below.

We can cast the pointer to JitScript in memory to see its contents as shown below.
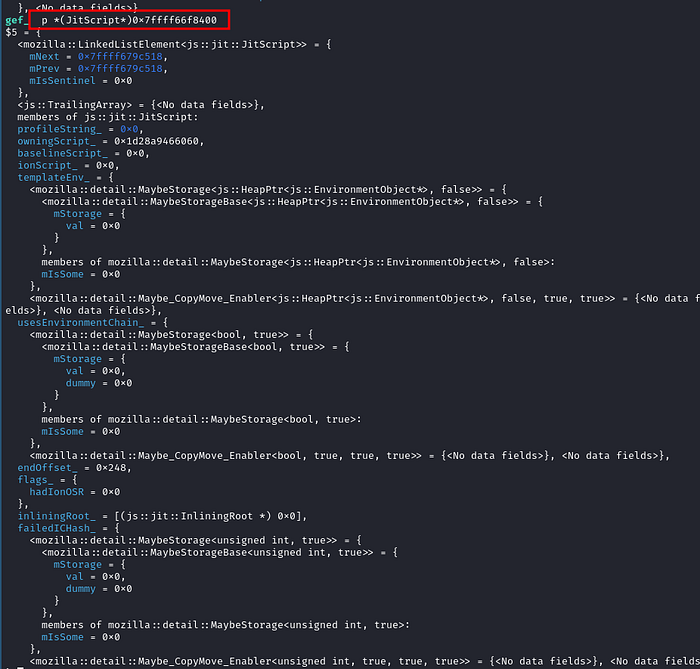
Since the IC entries are appended to the end of the JitScript, lets examine the pointers at the end of the JitScript. We can calculate the address of the first entry of the ICEntry by adding 0x128 bytes to the address of the JitScript as shown below.
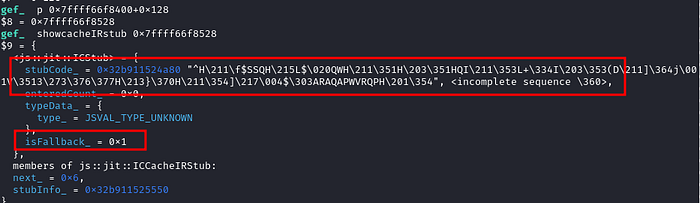
The ICEntry shown above is a Fallback IC entry, which means, the baseline interpreter has not triggered this bytecode yet to generate the CacheIR code for it. So the isFallback_ flag is set as true. Let’s move to next entries to see if we can find any other ICEntry with CacheIR code.
And, we have found a ICEntry which has a CacheIR code generated as shown below.
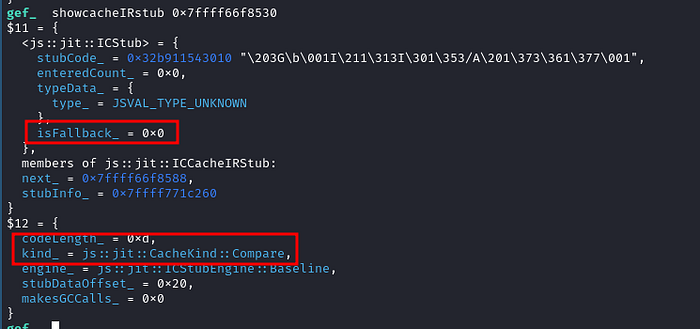
The ICEntry is for the JSOp::Compare bytecode and it is clearly not a Fallback IC code. So let’s examine the generated machine code for the CacheIR code.
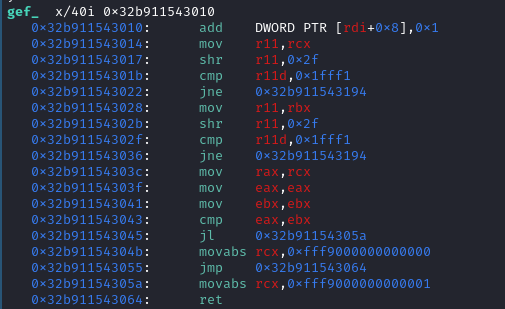
Don’t panic on looking at the generated machine code for the CacheIR code. Let me explain it to you.
The first instruction as shown below is doing but incrementing the enteredcount_ field of the ICStub in the ICEntry.
0x32b911543010: add DWORD PTR [rdi+0x8],0x1 The next three instruction are checking to see if the lhs of the compare operation is INT32 value. If its not a INT32 value, then the engine will jump to the next ICStub code.
0x32b911543014: mov r11,rcx │~
0x32b911543017: shr r11,0x2f │~
0x32b91154301b: cmp r11d,0x1fff1 │~
0x32b911543022: jne 0x32b911543194 The SpiderMonkey uses JSVals for representing each primitive types. The 16 MSB(most significant bits) in an 64 bit value is used for encoding which type of value it is. The value 0x1fff1 represents the JSVal type JSVAL_TYPE_INT32.
The next three instruction are also doing checking to see if the value is a INT32 value.
0x32b911543028: mov r11,rbx │~
0x32b91154302b: shr r11,0x2f │~
0x32b91154302f: cmp r11d,0x1fff1 │~
0x32b911543036: jne 0x32b911543194 Once these checks have been passed, the engine will perform the compare operation between the lhs and rhs value and sets the result as true or false as shown below.
0x32b91154303c: mov rax,rcx │~
0x32b91154303f: mov eax,eax │~
0x32b911543041: mov ebx,ebx │~
0x32b911543043: cmp eax,ebx │~
0x32b911543045: jl 0x32b91154305a │~
0x32b91154304b: movabs rcx,0xfff9000000000000 │~
0x32b911543055: jmp 0x32b911543064 │~
0x32b91154305a: movabs rcx,0xfff9000000000001 │~
0x32b911543064: ret The result is stored inside the RCX register as 0(false) or 1(true). This is how Inline Caches are generated for the each bytecode in SpiderMonkey. The Inline Cache that we saw till now is for the compare operation. Let’s dig in move to Add operations ICEntry to see its code.
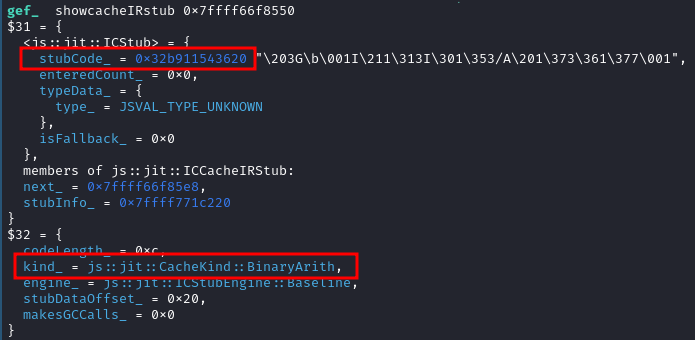
The generated machine code for the JSOp::Add bytecode is shown below
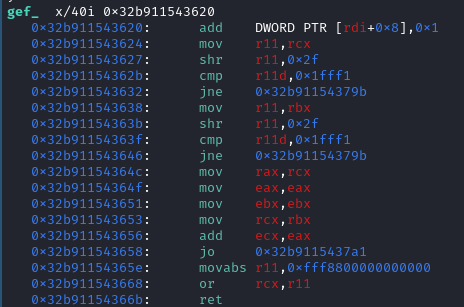
The machine code shown above also does the same checks as that are done for the Compare operation. At the end of the code, it is performing the Add operation using add instruction and converting the result into JSVal for further processing.
That shows how SpiderMonkey generates machine code for Inline Cache optimization for each bytecode in SpiderMonkey.
The CacheIR code disassembler that I wrote broke due to some changes in the newer bytecode version of CacheIR, otherwise, I would have shown the generated CacheIR code as well :(.
So that’s all for today :).